



The Right Fuel: Why Quality Data Is Everything in AI Systems
How Agentic RAG Transforms Business Intelligence from Promising to Precise


A staggering 80-85% of AI projects fail—twice the failure rate of traditional IT projects. The biggest culprit? Data quality issues, which cause over 70% of AI project failures. Yet every day, businesses feed their AI systems the equivalent of wrong fuel: poor quality data, outdated benchmarks, and domain-irrelevant information. Then they wonder why their "intelligent" systems produce insights that lead to costly mistakes.
The restaurant industry knows this pain intimately. I've watched operators make million-dollar location decisions based on AI analysis that used three-year-old demographic data or confused fast-casual metrics with fine dining benchmarks. The AI wasn't broken—it was just running on the wrong fuel.
The Fuel Problem: Garbage In, Intelligence Out?
Traditional business intelligence systems suffer from what I call "data diabetes"—they consume everything indiscriminately, unable to distinguish between high-quality nutrients and empty calories.
This indiscriminate consumption creates a dangerous disconnect between AI capability and business reality. Your AI model might be Claude Opus or GPT-4, but if you're feeding it stale, wrong, or irrelevant data to analyze a 2025 restaurant opportunity, you're essentially asking a Ferrari to run on cooking oil.
The evidence is stark: 99% of AI and ML projects encounter data quality issues, while 92.7% of executives identify data as the most significant barrier to successful AI implementation. Companies spend millions on the latest LLMs while their systems churn through irrelevant case studies, outdated industry reports, and generic benchmarks that have no business informing specialized decisions.
Consider a real scenario I encountered recently: A restaurant group's AI system recommended a location based on "strong demographic support" from analysis using traditional trade area distance calculations rather than actual visitor profile data from mobile tracking or credit card panels. The system confused local residents for potential restaurant customers—the AI wasn't wrong about who lives nearby, but that data was fundamentally irrelevant to understanding who actually visits restaurants in that area.
Enter RAG: Adding Your Data to the Mix
Before diving into the advanced capabilities of agentic systems, let's establish what Retrieval-Augmented Generation (RAG) actually is. RAG allows companies to add their internal knowledge and data to large language models, typically optimized for unstructured document repositories. Instead of relying solely on the LLM's training data, RAG systems retrieve relevant information from your specific business context—contracts, reports, manuals, historical data—and inject it into the AI's reasoning process.
Think of traditional RAG as adding a corporate library to your AI assistant. It can now reference your company's specific policies, past projects, and domain expertise rather than just generic knowledge.

Agentic RAG: The Smart Fuel Injection System
Agentic RAG represents a fundamental shift toward intelligent, domain-aware information retrieval that understands context, relevance, and data quality. It does everything traditional RAG does, plus adds autonomous reasoning capabilities and structured data retrieval.
Think of traditional RAG as a basic fuel pump—it delivers whatever's in the tank. Agentic RAG is like a sophisticated fuel injection system that:
Validates fuel quality before injection: Checks data freshness, source reliability, and domain relevance
Adjusts the mixture dynamically: Combines multiple data sources with appropriate weighting
Monitors performance continuously: Tracks accuracy and adjusts retrieval patterns based on outcomes
Maintains specialized knowledge: Builds domain-specific understanding over time
How Agentic RAG Actually Works
The "agentic" component means your RAG system doesn't just retrieve—it reasons about what to retrieve. Here's the difference:
Traditional RAG Flow:
User asks: "What's the market opportunity for a pizza restaurant in downtown Austin?"
System searches: "pizza restaurant market opportunity Austin"
Returns: Every document mentioning pizza, restaurants, markets, opportunities, or Austin
AI synthesizes: Produces analysis mixing food truck data, corporate cafeteria reports, and residential dining statistics
Agentic RAG Flow:
User asks the same question
Agent analyzes: "This is a commercial real estate question requiring demographic data, competition analysis, and location-specific factors"
Agent validates: "I need current data (last 18 months), commercial location metrics, and comparable concept performance"
Agent retrieves: Targeted search for recent demographic reports, competitive landscape data, and similar concept case studies
Agent synthesizes: Produces analysis using only relevant, validated information
While traditional RAG handles unstructured documents well, agentic RAG can also tap into structured data sources—databases, APIs, real-time feeds—with the intelligence to know which data sources are most relevant for specific business questions. For us, leveraging Snowflake's Cortex makes this structured data component of agentic RAG enterprise-ready, with the security and governance essential for business applications.

The Domain Knowledge Imperative
Here's where most AI implementations fail spectacularly: they treat all business questions as generic optimization problems. But domain expertise is irreplaceable context, not optional enhancement.
In restaurant feasibility analysis, understanding that a 15% food cost variance might be acceptable for a steakhouse but catastrophic for a quick-service concept isn't just helpful—it's essential for accurate analysis. Agentic RAG systems learn these domain-specific patterns and embed them into their retrieval and reasoning processes.
I've seen this play out repeatedly. Generic AI tools suggest labor cost targets that work for retail but destroy restaurant margins. Domain-aware agentic systems know to weight industry-specific benchmarks, seasonal patterns, and operational complexities that generic models miss entirely.
Security and Accuracy: The Trust Infrastructure
Dynamic business intelligence promises real-time insights, but without proper safeguards, you're trading reliability for speed. Agentic RAG addresses this through what I call "trust infrastructure":
Multi-Source Validation
Instead of relying on single sources, agentic systems cross-reference multiple data points and flag inconsistencies. If demographic data from the Census Bureau conflicts with commercial market research, the system doesn't just average them—it investigates the discrepancy and weights sources based on reliability and recency. Crucially, you can add human reasoning to the loop to validate results, with the agent remembering this expert input for future context and similar situations.
Confidence Scoring
Every analysis comes with quantified confidence levels based on data quality, source reliability, and pattern recognition. A restaurant feasibility study might be 95% confident about demographic analysis (recent, reliable data) but only 70% confident about competitive threats (limited comparable data available).
Audit Trails
Modern agentic RAG systems maintain complete lineage tracking—you can trace every conclusion back to its source data, understand why certain information was weighted more heavily, and identify exactly which data points drove specific recommendations.
The Restaurant Reality: Speed vs. Accuracy
The restaurant industry provides a perfect case study for why this matters. Traditional market research takes weeks and costs thousands. AI-powered analysis can deliver insights in minutes—but only if the underlying data infrastructure is sound.
I've seen this balance play out repeatedly. Generic AI tools suggest labor cost targets that work for retail but destroy restaurant margins. Domain-aware agentic systems know to weight industry-specific benchmarks, seasonal patterns, and operational complexities that generic models miss entirely.
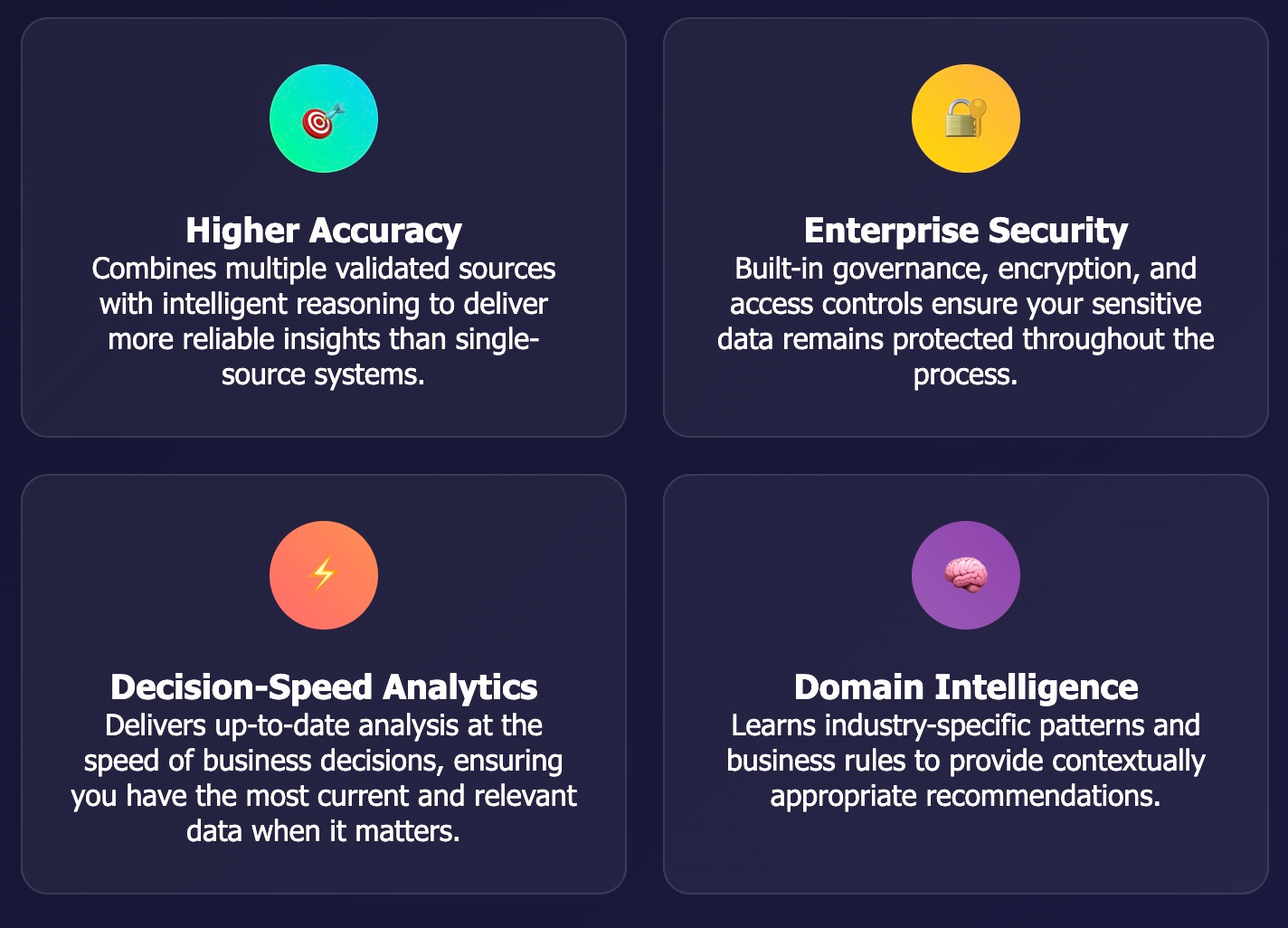
The key insight: competitive advantage comes not from having access to artificial intelligence, but from having access to actual intelligence—AI systems trained on the right data, configured for your specific domain, and constantly validated against real-world outcomes.
The Path Forward: Specialized Systems Thinking
The future of business intelligence isn't about more powerful AI models—it's about more intelligent data systems. Companies that understand this distinction will dominate their industries while competitors struggle with generic AI tools producing generic insights.
Building effective agentic RAG requires three foundational elements:
Domain-Specific Knowledge Architecture: Your system must understand your industry's unique patterns, metrics, and decision factors
Dynamic Data Quality Management: Continuous validation, source scoring, and relevance filtering
Human-AI Collaboration Loops: Expert oversight that improves system accuracy over time
The Bottom Line: Beyond the Fuel Analogy
You can have the most sophisticated AI engine in the world, but if you're feeding it the wrong data, you're just automating bad decisions faster. But here's where the fuel analogy breaks down in a critical way: when you put the wrong fuel in a car, it stops functioning and the damage is obvious immediately. When you put bad, poorly managed, or irrelevant data into an LLM, it will confidently generate beautiful prose filled with plausible-sounding nonsense. That's far more dangerous than a system that simply breaks.
This is why the challenge ahead isn't just about adopting better AI models—it's about fundamentally improving how we collect, validate, and manage data quality. This is a much taller order than diving into GPT systems, but it's the foundation that determines whether AI becomes a competitive advantage or an expensive mistake generator.
Agentic RAG represents the evolution from "smart retrieval" to "intelligent reasoning"—systems that don't just find information but understand what information matters for specific business contexts. The restaurant operators succeeding with AI aren't using the most advanced models—they're using the most thoughtfully designed data systems.
The question isn't whether your business will adopt AI-powered analytics. The question is whether you'll commit to the hard work of building data infrastructure that can fuel those systems effectively, or continue feeding them whatever's convenient and hoping for eloquent nonsense instead of actionable insights.
The urgency of improving data quality has never been greater. As AI systems become more sophisticated at generating convincing but potentially wrong answers, the stakes of getting data infrastructure right continue to rise. What data quality challenges are you grappling with in your industry? Share your thoughts in the comments.