

Your Knowledge Base Is Dead. Here’s What Replaces It.
The AI OS is assembling itself in public. Everyone’s building the plumbing. The linchpin is being mistaken for storage.

By Mike Lukianoff
In the last 90 days, Anthropic shipped Claude Cowork — a desktop agent that operates on your files, plans autonomously, and executes for hours. They shipped Claude in Chrome — a browser agent that scrapes websites, fills forms, and chains multi-step tasks on a schedule. They shipped 100+ connectors to Slack, Gmail, Google Drive, Notion, and GitHub. They shipped scheduled tasks that run while you sleep.
Anthropic isn’t alone. OpenAI, Google, and Microsoft are shipping similar capability at the same pace. In the enterprise vertical space, platforms like SignalFlare Navigator are building the same architectural patterns — autonomous agents, sandboxed execution, external data connectors — but purpose-built for organizational decision-making rather than individual productivity.
What’s happening is bigger than any single product. The plumbing of a new operating system is being assembled in public, at the consumer level and the enterprise level simultaneously. The consumer tools are moving fast. The enterprise tools are moving with more focus. Both are converging on the same underlying architecture.
But most of the conversation is about the tools — what agents can do, how to prompt them, which integrations exist. Very little focuses on what sits above the plumbing. Where does all of this accumulated activity go? Where does the organization’s knowledge live? Does any of it compound?
The tech stack is inverting. The knowledge base — a term most people associate with static document repositories — is about to become the most important layer. Not because the concept is new. Because everything around it finally changed.
We’ve Built This Stack Before
Each era of data infrastructure solved the last era’s problem and created the next one.
In the 1990s and 2000s, relational databases solved the problem of organizing transactions. Structured, schema-defined, reliable. The problem they created was rigidity. The world doesn’t fit in rows and columns.
In the 2010s, data lakes solved the scale problem. Store everything, figure it out later. The storage problem was solved. The insight problem wasn’t. Organizations drowned in data they couldn’t interpret. “Data swamp” entered the lexicon for a reason.
Now we’re in the knowledge base era, but most implementations haven’t caught up with what the term needs to mean. What organizations call “knowledge bases” are mostly document repositories — Confluence pages, SharePoint libraries, FAQ databases. Static by design. Disconnected from the systems that run the business. As I wrote in an earlier piece on domain intelligence and ontology, without shared meaning and domain structure, a knowledge base is just a filing cabinet with a search bar.
The Old Model Is a Document Graveyard
The problems with traditional knowledge bases are structural.
Static by default. Created once, maintained sporadically, decaying continuously. The half-life of business knowledge — competitive dynamics, pricing, customer behavior, regulations — is shorter than the update cycle of most knowledge management systems. The information is partially wrong at any given moment. The question is how wrong.
Disconnected from external reality. Most knowledge bases contain only internal information — no connection to competitors, the economy, what customers are saying on channels you don’t control. A knowledge base that doesn’t know what’s happening outside your walls isn’t intelligence. It’s memory. And memory without fresh input becomes increasingly wrong.
Retrieval, not reasoning. Traditional knowledge bases answer the question you asked. They don’t connect information across domains to surface the question you should be asking. Search gives you what you asked for. An analyst tells you what you missed.
No learning loop. The critical failure. Every user starts from zero. The 50th person to query the system gets the same experience as the first. Nothing compounds. In a world where AI agents can reason over information autonomously, a knowledge base that doesn’t learn from its own use is a depreciating asset.
The AI OS Is Assembling Itself
Literally — the new generation of AI infrastructure is being built, in large part, by AI. The AI OS isn’t just being designed by engineers and shipped to users. It’s being generated by the same models it’s built to support. The tools are building the tools.
The agent layer is live. At the consumer level, Cowork, Claude Code, and browser agents plan, execute autonomously, work with real files, and run for hours. At the enterprise level, platforms like SignalFlare Navigator deploy agents that coordinate across organizational teams and projects. The consumer tools use Linux virtual machines for local hosting and command-line execution on individual computers. The enterprise tools use isolated virtual containers — each customer, each project sandboxed separately — because at the organizational level, one agent’s mistake can’t be allowed to cascade into another team’s data.
This distinction matters. I wrote about why sandboxing is non-negotiable after a venture capitalist’s family photos were permanently deleted by an unsandboxed consumer agent. At the individual level, that’s a painful loss. At the enterprise level, the equivalent event could mean corrupted financial data or exposed customer records. The architecture has to account for this from day one.
The connector layer is live. 100+ consumer integrations and growing. Scheduled tasks that chain together — one Substack writer built a two-step automation where Chrome scrapes competitive data every Tuesday and Cowork analyzes the output 10 minutes later. At the enterprise level, SignalFlare Navigator connects to external data sources, proprietary models, and internal systems through a semantic layer that routes queries based on whether they need deterministic calculation or probabilistic reasoning. Different scale, same principle: continuous signal ingestion.
The memory layer is where the consumer and enterprise paths diverge most sharply. Cowork uses .claude.md files and folder-specific context to persist preferences across sessions — static configuration that tells the agent who you are and how you like to work. That’s a settings file.
SignalFlare Navigator uses a hierarchical memory structure — Threads for agent interactions, Projects that cluster threads with files and state, Teams that define domain-specific context and behavior. This isn’t conversation history stuffed into a context window, which is what most platforms call “memory.” It’s organizational memory that mirrors how businesses actually work. An agent behaves differently for a pricing analyst than a market researcher while sharing core infrastructure. I wrote about this architecture in detail in Building AI Infrastructure That Lasts. The difference between a settings file and organizational memory is the difference between automation that repeats and a system that learns.
The domain plugin layer is emerging. Anthropic ships 11 role-based plugins — Finance, Legal, Marketing, Sales, Data Analysis. Crude versions of what a proper domain ontology provides. In the vertical enterprise space, domain expertise coupled with AI OS architecture gets you there faster — SignalFlare Navigator, for instance, ships with industry ontology and semantic clarity based on deep domain understanding. That means fast time to value and fewer credits spent teaching the AI about your business. Far beyond the capability of generic plugins.
In the four bands of AI framework, consumer tools are shipping Band 2/3 capability — productivity and workflow automation. The Band 4 leap — full agentic decision intelligence — requires the knowledge, memory, and domain layers being built at the enterprise level now. The field is enormous. Domain expertise is what separates durable architecture from impressive demos.
The Knowledge Base as the Hub of the AI OS

A modern knowledge base is the hub where four streams converge.
Structured data: transactions, KPIs, operational metrics. Well-organized but narrow.
Unstructured data: documents, research, reports, reviews, communications. Broad but disorganized.
Team knowledge: institutional expertise, tribal knowledge, decision context. The most valuable and most fragile — it walks out the door when people leave. Hierarchical memory architecture — the kind that persists context at the thread, project, and team level — is how you make this durable.
External signals: market dynamics, economic indicators, competitive intelligence, customer sentiment. What connects your knowledge base to reality.
The knowledge base isn’t a destination for these streams. It’s a metabolism. Data flows in continuously. The system synthesizes across sources. Agents query it to reason and decide. Outcomes feed back in. The loop repeats and the system compounds.
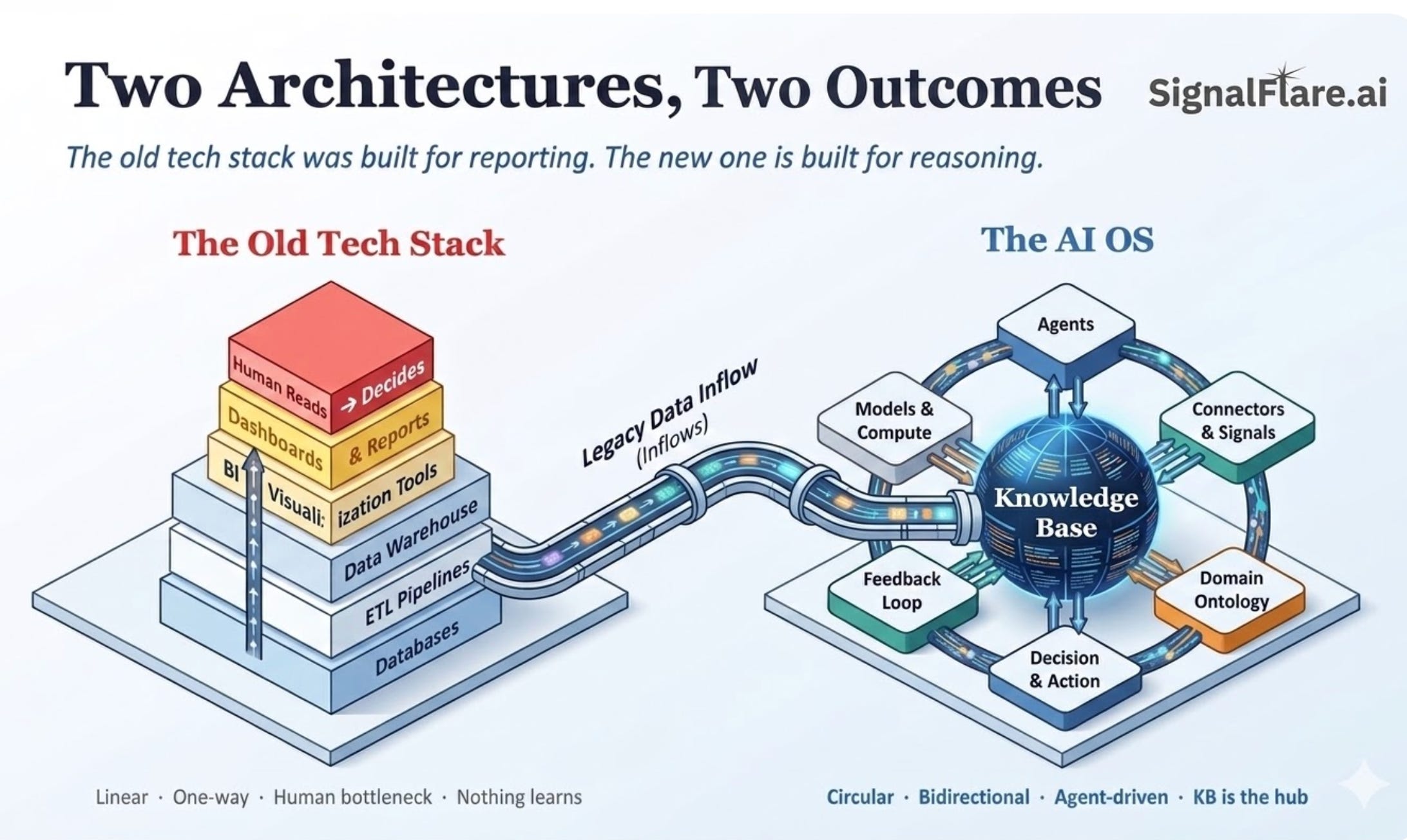
This is fundamentally different from the old tech stack: databases → ETL → warehouse → BI → dashboards → human reads → human decides. One direction. Nothing flows back. The human is the bottleneck and the only component capable of reasoning.
The new architecture is circular and agent-driven. The knowledge base sits at the center, not at the bottom. Everything connects to it. Everything enriches it.
But without proper ontology — shared definitions, entity relationships, business rules — a knowledge base is just a bigger data swamp. As I wrote in the domain intelligence piece, without this structure you’re injecting chaos through a clean protocol that makes everything look correct on the surface.
The Seven Layers — and Where Differentiation Lives

The emerging AI OS stack has seven layers. Understanding where you invest matters more than understanding what each layer does.
At the bottom: Compute & Models, Agents, and Connectors. Layers 1–3. These are commoditizing fast. Every major platform is shipping them. Table stakes within 18–24 months.
In the middle: The Knowledge Base — where signals converge, accumulate, and compound. Layer 4. The linchpin. Without it, everything above has nothing to work with.
At the top: Domain Ontology, Decision & Action, and Feedback Loop. Layers 5–7. This is where differentiation lives. Domain ontology is hard to build and harder to replicate. Decision logic grounded in business context compounds over time. Feedback loops that actually close are rare and valuable.
Invest in layers 4–7 while everyone else fights over layers 1–3, and you build a structural advantage that compounds. That’s not a prediction. It’s how compounding systems work.
The Compounding Effect
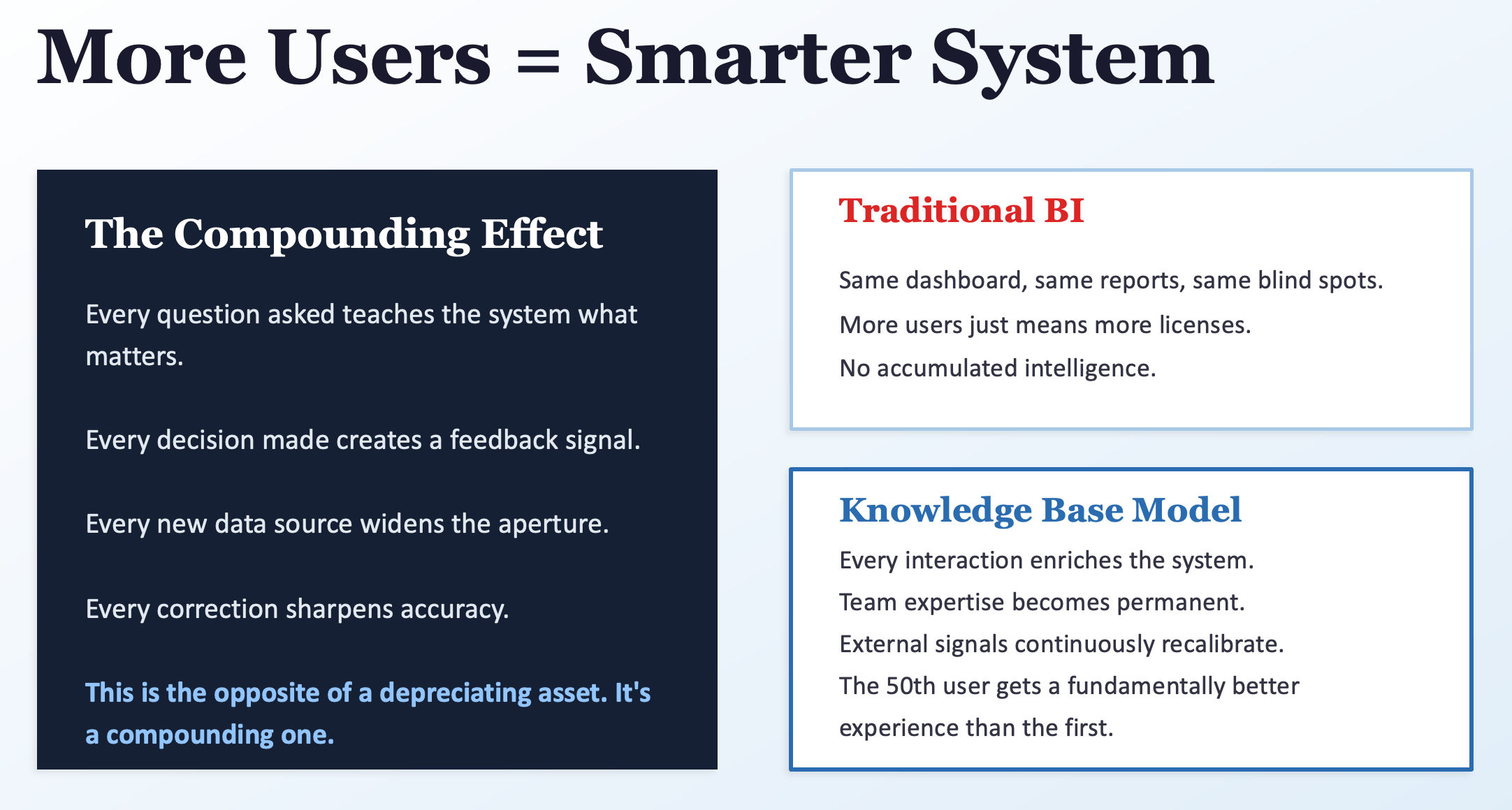
Traditional BI delivers the same dashboards, same reports, same blind spots regardless of usage. More users means more licenses. No accumulated intelligence.
A knowledge base model is different. Every question teaches the system what matters. Every decision creates a feedback signal. Every new data source widens the aperture. Every correction sharpens accuracy. The 50th user benefits from everything the first 49 taught the system.
This is why the memory architecture matters so much. A system that resets to zero on every interaction can’t compound. A system with hierarchical, persistent memory — where organizational learning accumulates at the thread, project, and team level — turns every interaction into an asset. A well-architected knowledge base gets more valuable with use, not less.
The Real Shift Is Organizational
The technology exists. The constraint is organizational.
Five shifts: from “knowledge is a document” to knowledge is a living network. From “data teams own the data” to everyone enriches the system. From “build it once, maintain it” to design it to learn continuously. From “measure what’s in the system” to measure decision quality. From “AI is a feature” to AI is the interface to your knowledge.
These aren’t technology problems. They’re leadership problems.
What This Means If You’re Starting from Where You Actually Are

None of this happens overnight. Most industries run on legacy stacks held together with duct tape and institutional memory. The data is messy, siloed, and hard to interpret. Culture moves slower than technology. Always has.
But you’re not at net-zero. A knowledge base can start with the data you have, organized around the high-value decisions you’re already making. Start with the questions that cost you the most when you get them wrong. Work backward.
The new stack can ingest, interpret, and gradually structure messy data that legacy systems left in a pile. Unlike the old approach — where bad data stayed bad until someone manually cleaned it — these systems progressively improve what they work with. The architecture will drag your legacy systems along. The earlier you start, the more learning cycles you accumulate.
Be cautious of AI-chat wrappers offering quick wins inside walled gardens. A thin interface on a single LLM that locks in your data is vendor dependency disguised as intelligence. When the next model leap happens, you want optionality, not a contract renegotiation. SignalFlare Navigator connects to over 150 models because innovation comes from the broad ecosystem, not any single provider. Locking into one model is a bet against the pace of change.
And above all — stay informed. Despite the naysayers and the “wait and see” contingent, this is the most disruptive technology in a generation. The organizations that treated the internet as a fad in 1998 spent a decade catching up. AI is following the same curve, faster. Staying informed isn’t optional. It’s a leadership responsibility.
The companies that win won’t have the most agents or integrations. They’ll be the ones whose knowledge base never stops learning. That starts with a decision to start — imperfect data, legacy systems, and all.
The Signal Flare is a reader-supported publication. If you found this useful, consider subscribing.